The most common objection to adopting a new security capability is not whether it works. It is whether it will fit. Security and engineering teams have spent years building a workflow that functions: code moves through a pipeline, findings land in a tracker, scanners feed dashboards, auditors get their evidence. Any tool that demands you tear that down and start over is a hard sell, no matter how good it looks in a demo.
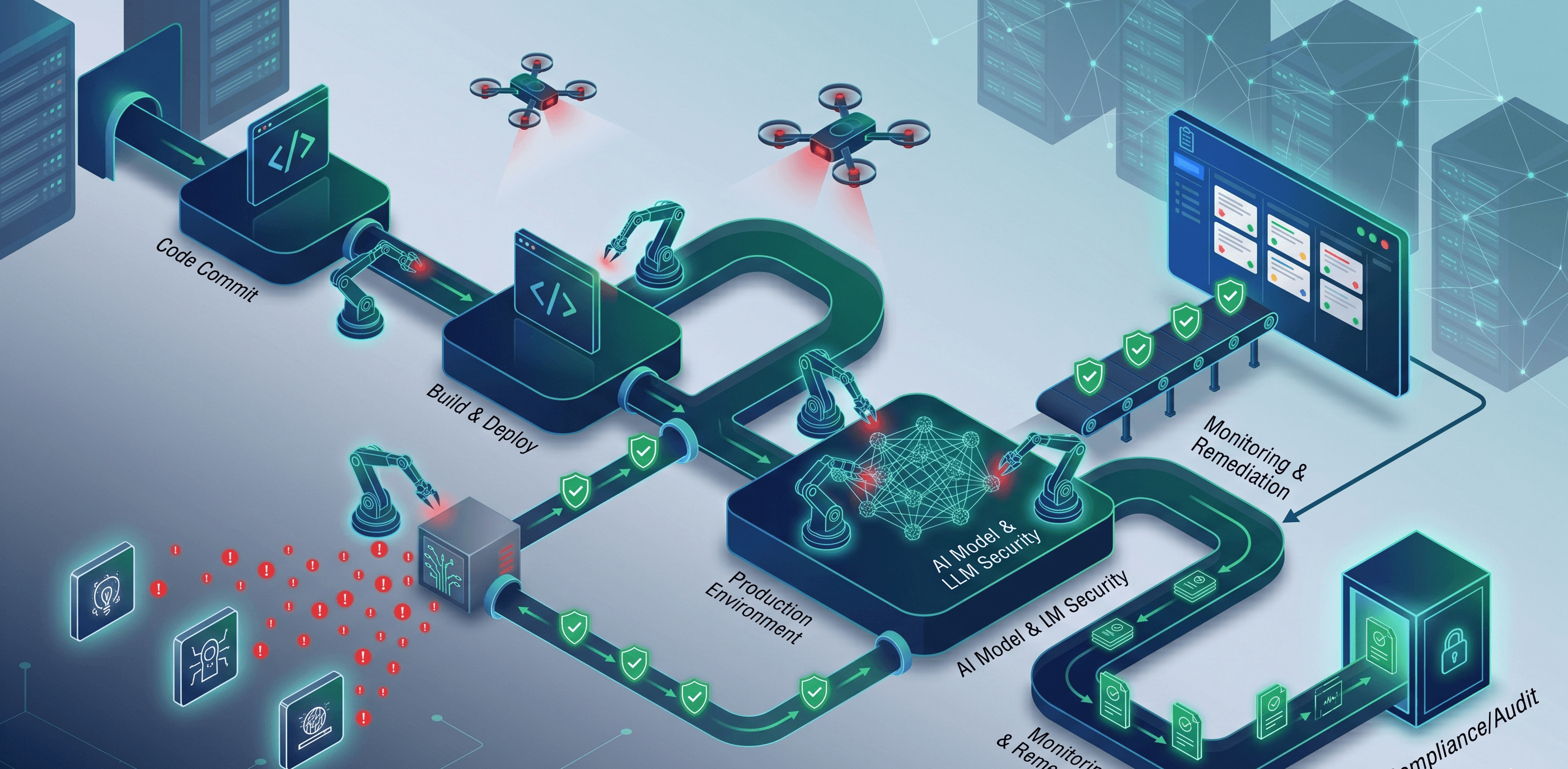
The good news is that autonomous red teaming platforms are designed to slot into the workflow you already have rather than replace it. Done well, autonomous red teaming becomes another participant in your existing pipeline: it discovers and attacks continuously, proves what is exploitable, and pushes results into the same tools your team already lives in. This article walks through exactly where it connects, from CI/CD to ticketing to scanners to evidence capture, and how it extends naturally into AI and LLM security testing without disrupting how your team works.
Start from the workflow, not the tool
It helps to picture the workflow that most security and engineering organizations actually run. Developers commit code, which moves through a continuous integration and delivery pipeline. Static and dynamic analysis tools run somewhere in that pipeline. Vulnerability scanners assess infrastructure and produce findings. Those findings flow into a ticketing system where they are triaged, assigned, and tracked. Periodically, a penetration test or audit produces a report that has to be reconciled against everything else. Evidence gets collected, often manually, to satisfy compliance.
The friction in this picture is well known. Scanners produce more findings than anyone can act on. Point-in-time tests describe a moment that has already passed. Evidence collection is a scramble. And the connective tissue between all these tools is often a person copying results from one system into another. Autonomous red teaming is most valuable not as a standalone island but as the layer that ties these pieces together with continuous, validated truth. The right question is not "what does the platform do?" but "where does it plug in?"
Connecting to CI/CD: testing on change, not on a calendar
The natural home for continuous security validation is the same pipeline that ships your software. When autonomous red teaming connects to your CI/CD process, testing can be triggered by change rather than by a calendar. A meaningful deployment can prompt the platform to re-examine the affected surface and confirm whether the new code introduced an exploitable path.
This is the difference between security that keeps pace with engineering and security that perpetually lags behind it. Because an autonomous platform runs as a coordinated system of agents rather than a human roster, it can begin immediately and work around the clock, so testing does not become the bottleneck in your release process. The cadence shifts from "we test every quarter" to "we test what changed, when it changed." Crucially, this integration does not require developers to adopt a new way of working. The pipeline they already use becomes the trigger, and results surface where they already look.
A platform like SpartanX is built around a continuous loop, discover, attack, validate, remediate, retest, that maps onto this pipeline naturally. The retest step is what makes CI/CD integration powerful: when a fix ships, the same exploit is attempted again automatically, so the pipeline itself confirms whether risk was actually reduced.
Connecting to ticketing and project management: findings where work happens
A finding that does not reach the person who can fix it is not useful, no matter how well it is validated. This is why integration with ticketing and project management systems is central to security workflow integration. Autonomous red teaming platforms should push validated findings directly into the trackers your teams already use, with the context an engineer needs to act: what the issue is, how it was exploited, the evidence, the affected component, and the recommended fix.
The benefit compounds when the findings are already exploit-validated. Instead of flooding your tracker with hundreds of theoretical issues that someone has to triage, the platform creates tickets only for what is genuinely exploitable. That keeps the backlog honest and keeps engineers focused on real risk rather than chasing false positives. Mature platforms go further into the remediation step itself. SpartanX, for example, can generate code fixes and open pull requests directly, and map findings to the relevant compliance controls, so the path from discovery to resolution lives inside the same tools your team uses to ship software. The work shows up where work already happens.
Connecting to scanners: turning noise into proof
Most organizations already own several scanners and vulnerability management tools, and they are not going to throw them away. They should not have to. One of the most practical roles for an autonomous red teaming platform is to sit on top of the tooling you already have and make it more useful.
The mechanism is validation. Scanners are good at breadth and speed but produce large volumes of findings with no proof of exploitability, which is where teams lose time. An autonomous platform can ingest those findings and then launch real attacks to confirm which ones actually matter, chaining them into working paths where possible. SpartanX does this through Targeted Attack Validation, ingesting findings from tools like Tenable, Rapid7, Qualys, Wiz, and Snyk, more than 150 in total, and collapsing thousands of alerts down to the handful that are truly exploitable, each backed by evidence. The outcome is that your existing investment in scanning becomes a source of validated truth rather than a source of noise. You are not replacing your tools; you are making them pay off.
Evidence capture: compliance as a byproduct
Evidence collection is one of the most tedious parts of any security workflow, and it is usually done under deadline pressure before an audit. Autonomous red teaming changes this by capturing evidence as a natural output of how it works. Because every finding is proven through actual exploitation, the proof-of-concept evidence already exists; it is generated at the moment the finding is validated, not reconstructed later.
When that evidence is mapped continuously to control frameworks such as SOC 2, PCI-DSS, HIPAA, ISO 27001, NIST, GDPR, and DORA, audit readiness stops being a fire drill. Instead of scrambling to assemble artifacts, you can show an auditor a living record of exploitable risk discovered, remediated, and confirmed fixed over time. Evidence capture becomes a byproduct of continuous security validation rather than a separate project, and the audit conversation gets easier because the proof was being collected all along.
Extending into AI and LLM security testing
The same workflow that handles your applications and infrastructure increasingly has to account for a new kind of asset: the AI systems and agents embedded in your products. This is where many existing tools fall short, because AI model security testing and LLM security testing require techniques that traditional scanners and pen test scopes were never built for.
Autonomous red teaming extends here naturally because the underlying approach, adversary simulation with exploit validation, applies just as well to AI systems as to web apps. Testing an LLM-backed feature means probing for prompt injection and jailbreaking, guardrail bypass, model extraction and data leakage, and the abuse of agent tools and workflows. These are not edge cases anymore; they are core risks for any product with AI in it. SpartanX treats AI systems as a first-class attack surface alongside web, APIs, networks, cloud, and identity, and demonstrated that depth by completing SecureLayer7's "Son of Anton" challenge end to end, proving guardrail bypass, system prompt and secret extraction, and multi-step prompt injection chains with working evidence.
The workflow implication is important: you do not need a separate program, a separate vendor, and a separate set of tickets for AI security. It flows through the same pipeline, the same tracker, and the same evidence trail as the rest of your testing. As AI becomes embedded in more of what you ship, that unified workflow is what keeps AI risk from becoming an unmanaged silo.
Reaching inside the perimeter without rewiring the network
A complete workflow does not stop at the internet-facing edge. Internal systems, Active Directory and identity infrastructure, machine identities, internal APIs, and east-west segmentation are where many real attacks ultimately play out. The concern teams have is that internal testing usually means complex network changes, and complexity is the enemy of adoption.
Autonomous platforms address this with lightweight internal deployment. SpartanX's NodeX capability runs the same agent swarm inside your environment through a hardened virtual machine that needs only outbound connectivity to operate, no site-to-site VPNs, no network bridging, and no inbound firewall rules. From there it exercises internal identity, machine identities, internal APIs, segmentation, and your own AI agent orchestration, with every finding still exploit-validated and audit-logged. The point for workflow purposes is that extending coverage inward does not require re-architecting your network. It fits the same operating model as everything else.
A realistic adoption path
One reason teams hesitate is the assumption that adopting a new testing capability means a long, disruptive rollout. In practice, autonomous red teaming tends to earn its place incrementally, and the lowest-friction entry point is usually validation of what you already have. Pointing the platform at your existing scanner output to confirm which findings are actually exploitable delivers immediate value, cuts the triage burden your team is already carrying, and requires almost no change to how anyone works. It is a fast way to prove the model on real data before expanding scope.
From there, teams commonly widen coverage outward across the external attack surface, then connect results to their ticketing and CI/CD systems so findings flow automatically, and finally extend inward with internal testing and into AI systems as those become priorities. Each step builds on the last, and none of them requires abandoning existing tools or processes. This staged path matters because it lets you demonstrate value at each stage rather than betting the whole program on a single large deployment. The platform becomes more deeply woven into the workflow as trust grows, which is exactly how durable adoption tends to happen.
The economics tend to follow the same gradual curve. Early on, the most visible return is time saved on triage and the false positives your team stops chasing. As coverage broadens and testing becomes continuous, the return shifts toward risk genuinely reduced, the exploitable paths closed before anyone outside could find them, and toward the audit time saved because evidence is being captured all along. Framing adoption this way, value at every step rather than a single leap, is usually what turns an evaluation into a program.
You stay in control
A reasonable worry about any autonomous capability is loss of control. "No humans required to execute" can sound like "no humans in charge." In a well-designed platform, the opposite is true. Autonomy applies to execution, not to authority. You define the scope, set the rules of engagement, approve actions, and direct outcomes, while the agents handle the relentless, repetitive work of probing, exploiting, and validating across the whole surface.
In practice this means visibility into what the system is doing, audit trails of every action, and the ability to scope and constrain testing to match your risk tolerance. The platform behaves like a tireless extension of your team that follows your commands, not a black box operating on its own agenda. That balance, full autonomy in execution paired with full human control over direction, is what makes continuous testing safe to run inside a production-grade workflow.
Putting it together
The reason autonomous red teaming fits modern security work is that it was designed around how teams already operate rather than against it. It connects to CI/CD so testing follows change. It pushes validated findings into the ticketing and project tools where work already happens. It sits on top of your existing scanners and turns their output into proof. It captures evidence continuously so compliance stops being a scramble. It extends into AI and LLM security testing through the same pipeline rather than a separate one. And it reaches inside the perimeter without forcing you to rewire your network.
None of this asks your team to abandon the workflow they have built. It asks the workflow to gain a new participant: an always-on adversary simulation that proves what is exploitable and routes that truth to exactly where it needs to go. For teams evaluating autonomous red teaming platforms, the integration question is the real question, and the answer that matters is how cleanly the platform disappears into the way you already work.
To see how SpartanX fits your stack and your existing tools, explore the platform or book a demo.
Ready to see SpartanX in action?
Discover how 600+ AI agents continuously test your entire attack surface with exploit-validated proof.